

Wobei uns künstliche Intelligenz bereits heute unterstützen kann
Vom 14.-16. Mai waren wir auf der „Minds Mastering Machines” (M3) Konferenz in Mannheim zu Gast und informierten uns über die neuesten Trends im Bereich künstlicher Intelligenz und maschinellem Lernen. Die interessantesten Themen und Talks stellen wir Ihnen hier vor.
Konzepte & Ideen
Was ist eigentlich dark Data?
Die Konferenz wurde mit der Keynote zum Thema Dark Data eröffnet. Der Begriff stammt von „Dark Matter“ ab, also dunkler Materie. Diese zeichnet sich dadurch aus, dass sie nicht sicht- oder messbar ist, aber trotzdem Einfluss auf unser Universum hat. Und tatsächlich gibt es auch Daten mit Einfluss auf unterschiedliche Entscheidungen, die in der Analyse ignoriert werden (Dark Data 1.0).
Dann gibt es Daten, welche von einem Unternehmen unbeabsichtigt veröffentlicht werden (Dark Data 2.0). Ein Unternehmen mag vielleicht nicht veröffentlichen wie viele LKW pro Tag ankommen. Aber veröffentlicht es diese Information nicht vielleicht über eine laufende Nummer auf einem Terminal? Dark Data 3.0 sind schließlich Informationen, die fehlen und gerade dadurch Aufmerksamkeit erzeugen.

Wie sicher ist maschinelles lernen?
Die Themen Sicherheit und Erklärbarkeit von KI-Modellen sind aktuell in aller Munde. Gerade in Bezug auf selbstfahrende Autos wird immer wieder gefragt, ob die Modelle sicher sind und vor allem warum sie manche Entscheidungen treffen.
Daher haben wir uns auch mehrere Talks zu diesem Thema angehört. Dabei stellte sich heraus, dass gerade Bilderkennungssysteme ausgetrickst werden können und möglichst in Regelsysteme eingebettet werden sollten. Das Thema Erklärbarkeit ist gerade in Bezug auf neurale Netze weiterhin sehr schwierig aber auch hier gibt es Ansätze.
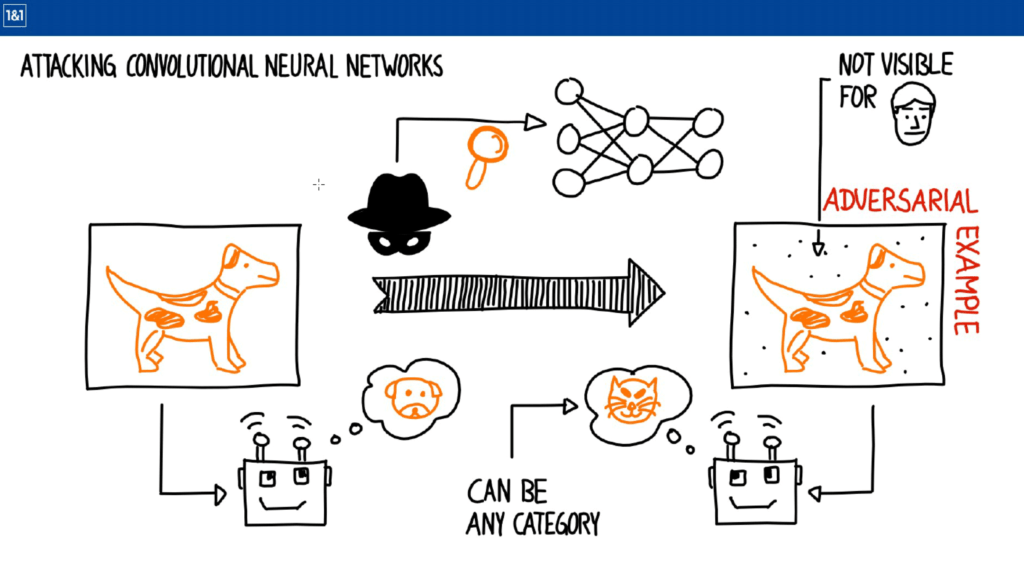
KI und das Gesetz
In mehreren Talks wurden spannende Fragestellungen bezüglich der Verwendung von automatisierten Systemen aufgezeigt.
Kann ein autonomes System einen Vertrag abschließen und wo liegt die Grenze?
Fallbeispiel: Eine Person bucht eine zusätzliche Fahrkarte für eine weitere Person, die „noch unbekannt“ ist. Diese Buchung der Fahrkarte wird vom System akzeptiert. Hier stellt sich die Frage, ob die Karte tatsächlich gültig ist, obwohl das Unternehmen in den AGBs vorgibt, dass die Namen der Personen nicht mehr änderbar sind. Nein? Was ist, wenn auf der Webseite angegeben ist, dass die Buchung vor der Bestätigung durch ein KI-System geprüft wird?
Wer ist Haftbar für ein autonomes System?
Unter Umständen sind viele verschiedene Firmen und deren Experten an der Entwicklung beteiligt. Wenn dieses System nun einen Fehler begeht. Wer ist haftbar? Diese Frage wird durch Unfälle von autonomen Autos aktuell sehr oft gestellt. Ein reger Austausch zwischen Juristen und KI-Experten findet zum Beispiel hier statt.
Und was ist mit dem Datenschutz?
Durch die DSG-VO ist dieses Thema aktueller denn je. Selbst wenn ein Unternehmen alle personenbezogenen Daten eines Kunden löscht. Wie geht man mit einem Modell um, welches diese Daten aller Kunden sehr genau abbildet? Wem gehört so ein Modell?
Praktische Anwendung – Wie KI bei der Qualitätskontrolle unterstützen kann
In vielen Branchen wird sehr viel Wert auf die Qualitätskontrolle gelegt. Experten begutachten in mühsamer Kleinarbeit Werkstücke auf der Suche nach Fehlern. Hier kann die Bilderkennung unterstützen und Vorschläge machen, welche Bereiche vermutlich einen Fehler enthalten. Auch Geräusche beim Pressen von Metall können einen Hinweis geben ob der Vorgang erfolgreich war. Hier kommt es auf die Zusammenarbeit zwischen Mensch- und Maschine an.
Ein Beispiel: Finden Sie den Fehler – Im Rahmen von Qualitätssicherungen können Ultraschallkameras verwendet und Abweichungen rot eingefärbt werden. Aufgrund der riesigen Datenmenge macht es Sinn, sich von neuronalen Netzen bei der Qualitätskontrolle unterstützen zu lassen.
Die richtigen Vorschläge machen
Aus Webshops kennt jeder den Satz „Andere Kunden kauften auch“. Was hier zum Einsatz kommt sind Recommender Systeme. Sie werden genutzt, um einem Kunden passende Vorschläge für weitere Artikel in seinem Warenkorb zu machen.
Dieses Prinzip lässt sich ausweiten auf andere Bereiche. Bei der Rechnungsstellung, der Kommissionierung oder jedem Bereich, in dem wir es mit Positionen zu tun haben. Hier wird analysiert, welche Positionen häufig zusammen auftreten und dem Mitarbeiter entsprechend Vorschläge unterbreitet.
Entscheidungsfindung unterstützen durch bestärkendes Lernen
In vielen Unternehmen gibt es Leitstände, in denen viel zusammenläuft und schnell Entscheidungen getroffen werden.
Fallbeispiel: Es ist gerade eine Laderampe frei geworden. Nun stellt sich die Frage, ob es Sinn macht, einen LKW vorzuziehen, damit die Abarbeitung im Lager schneller vonstatten geht oder bleiben wir bei First-In-First-Out?
Solche Entscheidungen werden tagtäglich hundertfach getroffen. Mit Reinforcement Learning können sogenannte Agenten darauf trainiert werden, diese Entscheidungen zu treffen. In einer simulierten Umgebung trainieren sie im Grunde mit dem Trial & Error Prinzip ohne Trainingsdaten. Sie bekommen lediglich eine Belohnung oder Bestrafung – je nachdem wie gut die Entscheidungen waren. Sobald nun ein „erlerntes Ereignis“ stattfindet, kann so ein Agent den Mitarbeitern im Leitstand eine Empfehlung geben.
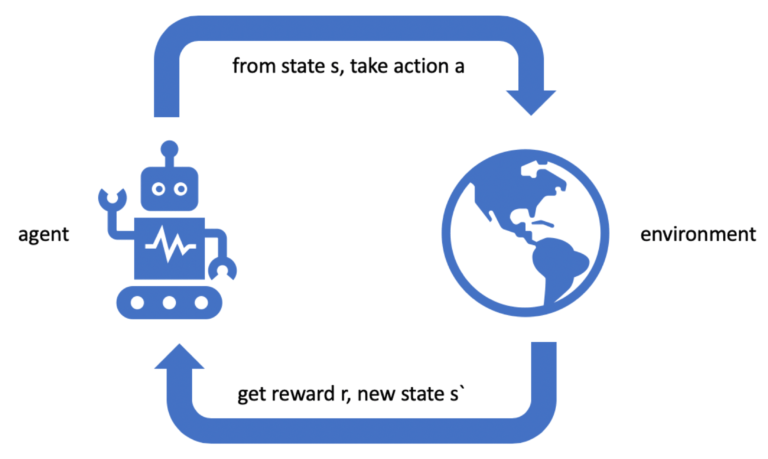
Die Umgebung ändert sich mit jeder Aktion des Agenten. Erreicht der Agent ein gestecktes Ziel, wird er belohnt. Mit der Zeit tritt ein Lerneffekt ein.
Mit Wörtern rechnen
Die Analyse von Texten (Text Mining) ist weiterhin eine der beliebtesten Disziplinen im Bereich der KI. Wollen Sie zum Beispiel eine Support-Anfrage direkt an die richtige Person leiten?
Dann macht es Sinn, die Ähnlichkeit der Anfrage mit bereits bekannten Anfragen zu berechnen. Hier hilft zum Beispiel Topic Modeling. So wird eine Anfrage automatisch einem Thema zugeordnet.
Ganz aktuell sind auch Entwicklungen im Bereich des Transfer Learnings. Dies bedeutet, dass vortrainierte neuronale Netze für neue Aufgaben wiederverwendet werden. Spannend wird es hier zum Beispiel bei der Erstellung von Systemen, die Fragen beantworten. Füttert man so ein vortrainiertes Netz mit eigenen Dokumenten (zum Beispiel Wiki-Artikel oder Dokumentationen) dann können sie im Anschluss Fragen zum Inhalt dieser Dokumente stellen. Die Ergebnisse in diesem Bereich sind wirklich beeindruckend.
Was hat maschinelles Lernen mit Kochrezepten zu tun?
Seit die Entwicklung verschiedener KI-Frameworks vor ungefähr 5 Jahren Fahrt aufnahm, verbessern sich die Werkzeuge für Entwickler und Data Scientists ständig. Ein Aspekt wurde dabei leider etwas vernachlässigt:
Die klassischen Themen der Softwareentwicklung – Robustheit, Reproduzierbarkeit und Versionierung.
Hier gibt es inzwischen Werkzeuge für die KI-Experten, um ihre Experimente besser zu strukturieren und reproduzieren zu können, zum Beispiel:
- DVS
- Sacred
- MLFlow
Denn genau wie ein Koch beim Kochen eines gelungenen Rezepts dieses reproduzieren möchte, wünscht sich auch ein Data Scientist immer das identische Ergebnis beim Durchführen eines Experiments.
Auch im Bereich DevOps sind mit Tensorflow Serving oder GraphPipe neue Möglichkeiten geschaffen worden, um in einer Docker-Container Umgebung verlässlich Modelle ausliefern und versionieren zu können.
Maschinelles Lernen im leogistics lab
Auch in diesem Jahr sind wir glücklich, erneut so viel von der M3 mitnehmen zu können. Wir freuen uns darauf, die gewonnenen Informationen in der Weiterentwicklung unserer Lösungen zu berücksichtigen sowie bei der Identifikation neuer Applikationen einfließen zu lassen.
Leider passt nur ein Bruchteil von unserem Wissen in diesen Blogartikel. Falls Sie also Fragen oder Interesse haben sich mit dem Thema KI oder Maschinellem Lernen auseinanderzusetzen, schreiben Sie uns in den Kommentaren oder melden sich direkt bei uns. Vielleicht gibt es ja auch in ihrem Unternehmen Prozesse, in denen diese Technologien Einsatz finden.
Bei Fragen zu diesem oder auch anderen Themen im Blog wenden Sie sich gerne am blog@leogistics.com.
Hendrik Hilleckes
Development Architect
